어제를 마지막으로 함께해 주신 교수님과 이별의 아쉬움을 뒤로 한 채로 새로운 교수님이 오셨습니다.
먼저 HTML에 대해 알려주셨습니다. 5일이란 과정을 함께 하신다고 하셨는데 너무 짧은 거 같네요.. 잘 배우겠습니다!
여러분, 사이트를 적어나갈때 항상 접두사처럼 붙는 www, (물론 http(s)://도 있지만..) 이게 무슨 뜻인 줄 아시나요? 바로 world wide web이라는 뜻입니다. (사실 이쪽에 흥미 있던 저에게는 조오금 알던 사실이지만 다시 들어보니 너무 좋았어용
그때 브라우저가 출현하게 되었고, 사용자가 폭발적으로 증가하게 되는 계기가 되었다고 하셨죠..
이 뒤에는 이론내용이라 조오금 지루 할 수도 있지만 잘 읽어봐요!
IP주소 : 인터넷에 연결된 모든 컴퓨터에 부여되는 고유의 식별 주소를 의미한다. 이 주소는 32비트(4byte)로 표현되며, 표기할 때에는 4개의 십진수를 점(.)으로 구분하여 표시한다.
도메인이름서버 (DNS, domain name server) : 도메인이름을 IP 주소로 전환시켜 주는 시스템
URL (Uniform Resource Locator) : URL은 웹 상에서 서비스를 제공하는 각 서버들에 있는 파일들의 위치를 명시하기 위한 체계 접속해야 될 서비스의 종류, 서버의 위치(도메인 네임), 파일의 위치를 포함
이렇게 보면 컴퓨터 언어는 정말 다 줄임말인 게 보이더라고요..? 풀네임을 알게 되니 조금 신선했어요.
HTML 문서의 기본구조는 이러합니다.
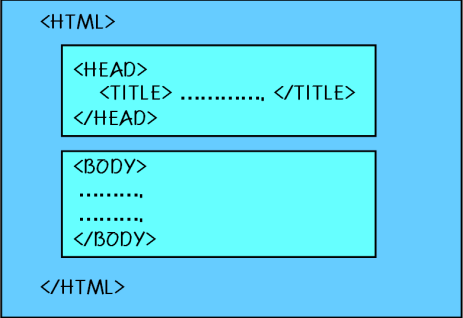
태그의 종류에는
글자, 문단, 목록 태그가 있어요
글자 태그는 사용자에게 보여주는 태그, 입력태그가 있어요
<Hn> 태그는 제목에 주로 사용하고, <p> 태그는 문단을 구분하는 태그랍니다.
그리고 목록 태그는 <OL>, <UL>, <LI> 태그가 있어요.
OL은 목록의 제목 앞에 사용하고, UL태그는 종료할 때 쓰고, LI태그는 알아서 순서가 생기도록 해준답니다.
마지막으로 <A> 태그는 무조건 herf(링크)의 정보가 들어있다는 걸 알고 들어가면 좋을 거 같아요.
멀티미디어장으로 넘어갔는데
여기선 이미지 태그와 테이블 태그를 알려주셨어요.
이미지태그는 이미지를 삽입할 때 사용하고, src속성을 가지고, 실제 이미지 위치값이 들어있는 게 특징입니다.
테이블 태그는 행과 열로 되어있고, 테이블에 행을 삽입하는 <TR>, 행안에 셀을 만들어주는 <TD> 태그가 있습니다.
프레임 태그와 입력 태그장으로 넘어와서,
입력태그는 Form태그 내에 있어야 하는 Form 태그,
input 태그에는 라디오버튼과 체크박스가 있는데, 라디오 버튼은 여러 개의 옵션 중 한개만 선택하도록 하는 입력기능을 제공하고, 체크 박스는 여러개의 항복을 동시에 선택할 수 있는 입력기능을 제공한답니다.
팝업메뉴와 리스트박스는 위에 라디오버튼과 체크박스 대신 사용할 수 있는 기능입니다,
팝업메뉴는 한 번에 한 가지 항목만 선택 가능하고, 리스트 박스는 동시에 여러 개를 선택 가능하다는 게 특징입니다.
다음장으로 빠르게 넘어와서
클래스 선택자는 동일한 태그이더라도 다른 스타일을 적용하고 싶은 경우가 있을 때 class속성을 추가해서 사용할 때 부릅니다.
id선택자는 클래스 선택자와 유사한 기능을 하지만 ID속성값은 한 문서에 한 번만 사용할 수 있다는 점에서 차이가 있다고 배웠습니다.
직전 교수님까지는 Anaconda를 활용해 jupyter notebook이라는 프로그램을 사용했는데 이번부터는 colab을 활용해서 가르쳐주신다고 하셨습니다.
초기설정에서 글꼴은 consolas로 하라고 하셨습니다. 일반 글꼴로 해버린다면 I와 l과 같은 문자들을 구별하기 힘들기 때문이죠.


데이터 수집을 위해 사이트 접속을 했는데 정적크롤링이면 나이스 하고 그냥 크롤링하면 되지만, 동적크롤링과 같이 암호 같은 문장이 걸려있으면 아래와 같이 출력되어 크롤링하기 쉽지 않아요..

!pip install konlpy
!pip install koreanize-matplotlib # 한글이 깨지는걸 사전에 방지from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import datetime
from pytz import timezone
import warnings
warnings.filterwarnings('ignore')

본격적으로 크롤링하는 법을 배워보도록 합시다.
배울 때는 '네이버 랭킹뉴스'에서 배웠습니다.
# 1) 데이터 프레임 생성
data = pd.DataFrame(columns=['언론사명', '순위', '기사제목', '기사링크', '수집일자'])
# 2) 언론사별 랭킹 뉴스 URL
url = 'https://news.naver.com/main/ranking/popularDay.naver'
# 3) url 접속하여 html 가져오기
html = urlopen(url)
# 4) HTML 태그 파싱하여 변환
soup = BeautifulSoup(html, 'html.parser')
# 5) 네이버 랭킹뉴스 정보가 들어 있는 div만 추출 -> rankingnews_box만 가져오기
div = soup.find_all('div', {'class':'rankingnews_box'})
# 6) 네이버 랭킹뉴스 기사 제목, 언론사 등 데이터 크롤링
for index_div in range(len(div)):
#언론사 추출
strong = div[index_div].find('strong', {'class' : 'rankingnews_name'})
press = strong.text
# 5개 순위 기사 정보 추출
ul = div[index_div].find_all('ul', {'class' : 'rankingnews_list'})
for index_r in range(len(ul)):
li = ul[index_r].find_all('li')
for index_l in range(len(li)):
try:
rank = li[index_l].find('em', {'class': 'list_ranking_num'}).text #여기까지만 하면 태그만 담김 .text를 붙여줘야댐
title = li[index_l].find('a').text
link = li[index_l].find('a').attrs['href']
# print(rank, title, link)
temp_df = pd.DataFrame({'언론사명': press,
'순위':rank,
'기사제목':title,
'기사링크':link,
'수집일자':datetime.datetime.now(timezone('Asia/Seoul'))
}, index=['순위'])
data = pd.concat([data, temp_df], ignore_index=True)
except:
pass
print('Complets of', rank, ':', title)
print('-' * 50)
print(data)
data.to_csv('네이버랭킹뉴스_많이본뉴스_20240718.csv', encoding = 'utf-8-sig', index=False)CP949도 한글을 안 깨지게 해주지만 utf-8-sig도 안깨지게 해 준답니다.
*rankingnews_box, rankingnews_list는 사이트에서 F12를 누른 개발자 상태에서, 내가 원하는 데이터만 끌고 오고 싶은데, 그것을 끌고 온 명사입니다,
이제 크롤링한 데이터를 시각화하는 법을 알려주셨습니다.
import matplotlib.pyplot as plt
import seaborn as sns
import koreanize_matplotlib
import konlpy
from wordcloud import WordCloud
워드 클라우드를 위한 전처리는
#기사제목을 텍스트 뭉치 변환해서 워드 클라우드 시각화
text = ' '.join(title for title in data['기사제목'].astype(str))
text
font_path ='/content/BMDOHYEON_ttf.ttf'
wc = WordCloud(width=1000, height=700, font_path=font_path).generate(text)
plt.axis('off')
plt.imshow(wc, interpolation='bilinear')
plt.show()폰트를 이용하여 데이터 시각화를 출력해 보았습니다.

마지막으로 많이 본 뉴스와 댓글이 많은 뉴스를 총 두 가지를 한 번에 코드를 쓰며 비교하는 법을 배웠는데
그렇게 어렵진 않게 풀었습니다. (복붙 해서 코드 조금만 수정하면 되니까.....)
# 1) 데이터 프레임 생성
re_data = pd.DataFrame(columns=['언론사명', '순위', '기사제목', '기사링크', '수집일자'])
# 2) 언론사별 랭킹 뉴스 URL
url = 'https://news.naver.com/main/ranking/popularMemo.naver'
# 3) url 접속하여 html 가져오기
html = urlopen(url)
# 4) HTML 태그 파싱하여 변환
soup = BeautifulSoup(html, 'html.parser')
# 5) 네이버 랭킹뉴스 정보가 들어 있는 div만 추출 -> rankingnews_box만 가져오기
div = soup.find_all('div', {'class':'rankingnews_box'})
# 6) 네이버 랭킹뉴스 기사 제목, 언론사 등 데이터 크롤링
for index_div in range(len(div)):
#언론사 추출
strong = div[index_div].find('strong', {'class' : 'rankingnews_name'})
press = strong.text
# 5개 순위 기사 정보 추출
ul = div[index_div].find_all('ul', {'class' : 'rankingnews_list'})
for index_r in range(len(ul)):
li = ul[index_r].find_all('li')
for index_l in range(len(li)):
try:
rank = li[index_l].find('em', {'class': 'list_ranking_num'}).text #여기까지만 하면 태그만 담김 .text를 붙여줘야댐
title = li[index_l].find('a').text
link = li[index_l].find('a').attrs['href']
# print(rank, title, link)
temp_df = pd.DataFrame({'언론사명': press,
'순위':rank,
'기사제목':title,
'기사링크':link,
'수집일자':datetime.datetime.now(timezone('Asia/Seoul'))
}, index=['순위'])
re_data = pd.concat([re_data, temp_df], ignore_index=True)
except:
pass
print('Complets of', rank, ':', title)
print('-' * 50)
print(re_data)
re_data.head()
re_text = ' '.join(title for title in re_data['기사제목'].astype(str))
re_text댓글이 많은 뉴스 워드 클라우드를 위한 전처리 과정은 이러합니다.
re_wc = WordCloud(width=1000, height=700, font_path=font_path).generate(re_text)댓글이 많은 뉴스 워드 클라우드는 이러하고,
fig = plt.figure(figsize=(15,5))
rows = 1
cols = 2
ax1 = fig.add_subplot(rows, cols, 1)
ax1.imshow(wc, interpolation='bilinear')
ax1.set_title('언론사별 많이 본 뉴스')
ax1.axis('off')
ax2 = fig.add_subplot(rows, cols, 2)
ax2.imshow(re_wc, interpolation='bilinear')
ax2.set_title('언론사별 댓글이 많은 뉴스')
ax2.axis('off')
plt.show()두 개를 한 번에 시각화하는 법은 이러합니다.

그런데 이렇게만 보면 솔직히 예쁘기는 한데 가독성이 떨어지잖아요, 그래서 막대그래프로 나타내는 법도 배웠습니다.
# 기사 제목 텍스트 변환
d_text = ' '.join(title for title in data['기사제목'].astype(str))
m_text = ' '.join(title for title in re_data['기사제목'].astype(str))# 명사 단어 추출
komoran = konlpy.tag.Komoran()
d_nn = komoran.nouns(d_text)
m_nn = komoran.nouns(m_text)# 데이터 프레임으로 변환
d_word_df = pd.DataFrame({'word': d_nn})
m_word_df = pd.DataFrame({'word': m_nn})
# 단어 수 컬럼을 추가
d_word_df['count'] = d_word_df['word'].str.len()
m_word_df['count'] = m_word_df['word'].str.len()# 글자수가 2개 이상인 단어만 사용
d_word_df = d_word_df.query('count >=2 ')
m_word_df = m_word_df.query('count >=2 ')# 단어의 빈도표 만들기
d_group_df = d_word_df.groupby('word', as_index=False).agg(n=('word', 'count')).sort_values('n', ascending=False)
m_group_df = m_word_df.groupby('word', as_index=False).agg(n=('word', 'count')).sort_values('n', ascending=False)# 단어 빈도 막대 그래프
# 가장 많이 본 뉴스와 댓글이 많은 뉴스의 단어 빈도수 비교
fig, axes = plt.subplots(1, 2, figsize=(15,5)) # 차트 나눠서 그림.
plt.suptitle('가장 많이 본 뉴스와 댓글이 많은 뉴스의 단어 빈도수 비교')
sns.barplot(data=d_group_df.head(10), y='word', x='n',ax=axes[0])
axes[0].set_title('가장 많이 본 뉴스')
sns.barplot(data=d_group_df.head(10), y='word', x='n',ax=axes[1])
axes[0].set_title('댓글이 가장 많은 뉴스')
plt.show()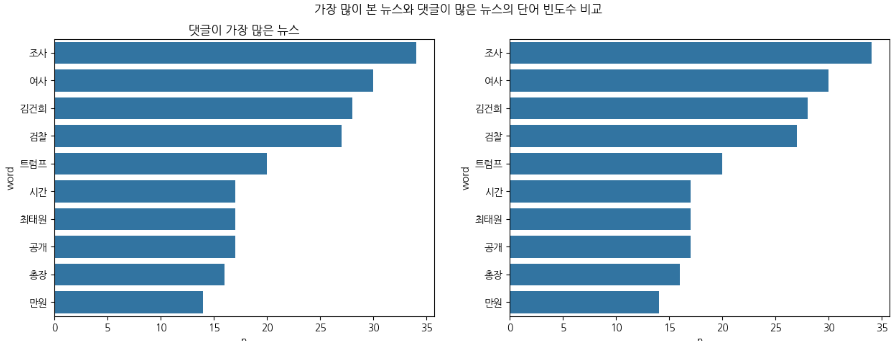
가로형 막대로 나타냈는데, 세로형 막대도 그릴 수 있습니다.
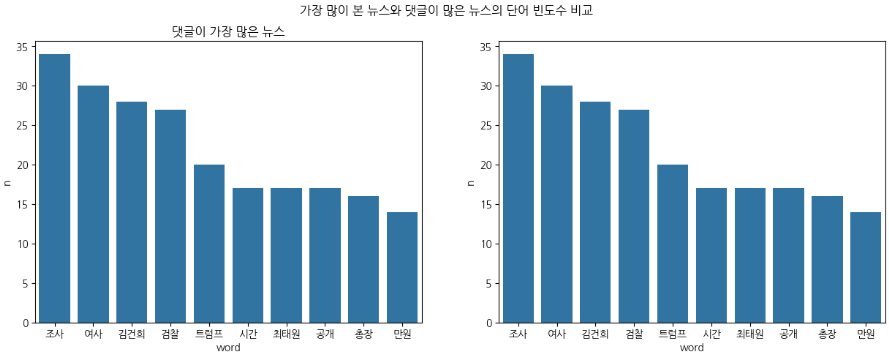
# 단어 빈도 막대 그래프
# 가장 많이 본 뉴스와 댓글이 많은 뉴스의 단어 빈도수 비교
fig, axes = plt.subplots(1, 2, figsize=(15,5)) # 차트 나눠서 그림.
plt.suptitle('가장 많이 본 뉴스와 댓글이 많은 뉴스의 단어 빈도수 비교')
sns.barplot(data=d_group_df.head(10), y='n', x='word',ax=axes[0])
axes[0].set_title('가장 많이 본 뉴스')
sns.barplot(data=d_group_df.head(10), y='n', x='word',ax=axes[1])
axes[0].set_title('댓글이 가장 많은 뉴스')
plt.show()
# 세로 그래프로 변경하고 싶으면 y와 x의 값을 변경!!다만, 세로형 그래프로 바꾸면 가로형과 다르게 좌우 공간이 부족해져 나중에는 가독성이 떨어지므로 가로형 그래프를 추천하신다고 하셨습니당.
교수님과 첫 진도를 나가보았는데, HTML에 대해서도 조금이었지만 배울 수 있는 기회가 되어 좋았고, 이제 내가 할 프로젝트에 점점 다가오고, 실전에 가까워진다는 생각에 더더욱 집중해서 듣게 되는 수업이 되었습니다.
앞으로도 파이팅 하며 잘 듣고 하산하겠습니다!

'ABC 부트캠프' 카테고리의 다른 글
| [13일차] ABC 부트캠프_동적 크롤링 (2) | 2024.07.22 |
|---|---|
| [12일차] ABC 부트캠프 ESG데이! (3) | 2024.07.21 |
| [10일차] ABC 부트캠프 데이터 집계 (0) | 2024.07.17 |
| [9일차] ABC 부트캠프 데이터 처리 심화_반응형 그래프 (0) | 2024.07.16 |
| [8일차] ABC 부트캠프 데이터 집계와 시각화(히스토그램) (2) | 2024.07.15 |



