[8일차] ABC 부트캠프 데이터 집계와 시각화(히스토그램)
반복된 복습을 통해 이제 드디어 다른 사람과 비슷하게 진도를 따라가며 배워갈 수 있었다.
배움의 미학이라는 게 이것인가 깨닫게 되는 시간이었다..!

오늘도 행복한 python 시작!
3.4. 함수를 활용한 여러 변수 선택
import pandas as pd
df_pr = pd.read_csv('./data/PulseRates.csv')
df_pr우선 df_pr에 csv파일을 저장해 줍니다.
# filter( ) 메서드에서 변수 이름 패턴을 활용한 선택
## regex : 정규표현식(regular expression)
## '^s' : 's'로 시작하는 이름/텍스트
## 's$' : 's'로 끝나는 이름/텍스트
df_pr.filter(regex='se')

regex는 라벨 이름에 패턴을 가지고 중규식에서 'se'라는 문자열을 포함한 라벨이 있다면 선택됩니다.
그래서 출력해 보면 좌측과 같이 se가 들어있는 문자열만 출력됩니다.
위의 함수에서는 'se'라는 문자만 들어가도록 했는데 ^s와 같이 ^s를 입력하게 된다면 그 문자로 시작하는 이름을 출력하고, 문자열$를 선택하면 문자열로 끝나는 이름을 출력하게 됩니다.
pandas.DataFrame.select_dtypes ← 저번 일차에 알려드렸던 pandas사이트를 활용해 검색해 보고 참고하세용
여기서 얻을 수 있는 것은 include, exclude list-like의 형태를 전달 가능 하다고 나와있네요!
3.5. 조건을 활용한 관측치 선택
df_ins['age'] < 30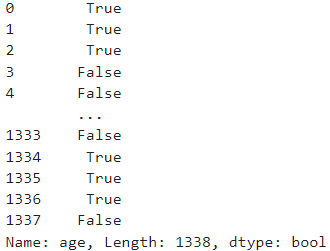
series < int 형태가 나오는데
series는 여러 개의 항이 나오는데 series에 대한값 중에 <int인 경우에 True or false로 출력
import pandas as pd
df_ins = pd.read_csv('./data/insurance.csv')하기 전에 먼저 실행!
# 위에 출력된 bool을 cond에 저장
cond = df_ins['age'] < 30
df_ins.loc[cond]
cond에 저장하고,
그에 해당하는 값들을 출력해서 나온 결과입니다.
417 rows * 7 columns
cond1 = df_ins['age'] < 30
cond2 = df_ins['sex'] == 'female'
cond = cond1 & cond2 #and 연산
df_ins[cond]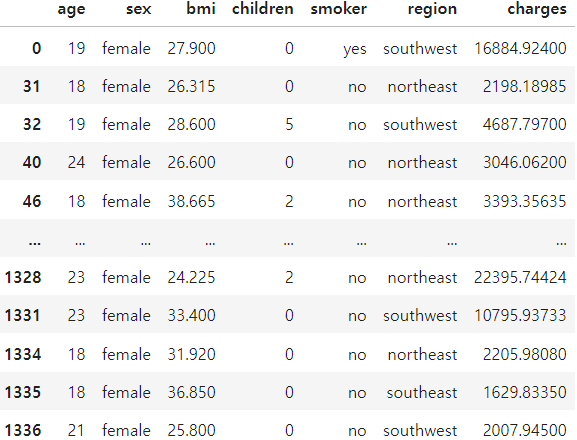
여기 series에서 and는 &, or은|, not은~로 쓸 수 있습니다.
출력해 보면 female이고, and가 들어갔으므로, 30 미만과 female 둘 다 충족되는 결과만 출력된 화면입니다
201 rows * 7 columns
번외.
df_ins[(df_ins['age'] < 30) | (df_ins['sex'] == 'female')]
|가 들어갔으므로 or의 의미로
둘 중에 하나만 충족되면 되므로 옆 사진처럼 출력됩니다.
878 rows * 7 columns
isin 속하면 True 아니라면 False
True 라면 두 지역 중에 하나 아마 or조건문으로 바꿀 수 있다.
df_ins['region'] # 변수 region의 수준 목록 확인 및 관심 수준 선택
cond1 = df_ins['region'].isin(['southeast','northwest'])
(df_ins['region'] == 'southeast') | (df_ins['region'] == 'northwest')- 여기서 isin을 이용한다면 True 혹은 False 둘 중 하나만 충족해도 되는 or문처럼 사용 가능하다.
- isin대신 |을 사용가능 하다.
df_ins.loc[cond1]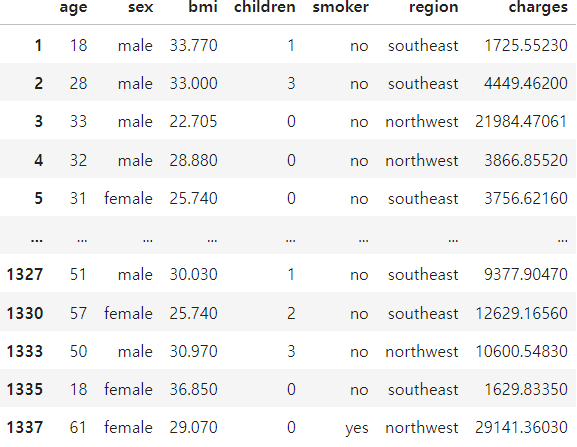
마지막으로 cond1을 불러와주면 좌측의 화면과 같이 출력된다.
689 rows * 7 columns
Series의 str 메서드 활용
활용하면,
str(문자열 중에) startswith, endswitch, contains 각각 시작하면, 끝나면, 포함하면이라는 뜻을 가짐.
예를 들면. 아래처럼 활용된다.
df_sp
df_sp['parental level of education'].str.startswith('b')
df_sp['parental level of education'].str.endswith('college')
df_sp['parental level of education'].str.contains('degree')
#각각 따로 실행
Series의 between 메서드 활용
활용하면 이상, 이하라는 의미를 한 번에 가짐.
예를 들면,
df_sp['math score'].between(80, 89.9)
Series에서 not을 이용하려면 ~을 적으면 된다.
3.6. 함수를 활용한 부분 관측치 선택
# df_ins.sample(frac=0.005)
df_ins.sample(n=10)행을 선택하는데 sample과 nlargest, nsmallest가 있다. 그중 먼저 sample은 무작위 추출이란 의미를 갖는다.
그래서 실행할 때마다 결과 달라진다
그리고 frac를 사용하면 모집단(1000개 라면 0.005)라고 해두면 그 비율에 따라서 5개의 결과가 나온다
df_ins.nlargest(10, 'charges')nlargest 가장 큰 것 중 n개 그럼 뒤에 나온 것처럼 10개를, charges에서 가장 큰 것이라는 의미.
df_ins.nsmallest(10, 'charges')nmallest도 같은 경우.
3.7. 중복값 제거
drop_duplicates()를 활용해서 중복값을 제거한 목록 생성 가능.
df_ins.drop_duplicates(subset=['sex', 'region'])위처럼 subset를 이용하면 성별, 지역이 중복되는 것을 제거한 목록이 생성됨.
3.8. 관측치 정렬
오름차순과 내림차순이 있다. 그중, ascending은 내림차순을 의미한다.
아래와 같이 False, True를 활용하여 오름차순, 내림차순을 응용해 보자.
df_ins = df_ins.sort_values('age', ascending=False) #ascending이 아니다. = 오름차순
df_ins# 복수 기준의 설정
df_ins.sort_values(['age', 'charges'], ascending=[True, False])
#age가 같으면 오름차순, charge가 다르면 내림차순위는 복수개가 나왔을 때 하는 법이다.
번외.
# age 순 데이터 정렬
df_ins.sort_values('age')# 원본 데이터는 영향 없음
df_ins.head()# 원본 데이터의 정렬
df_ins = df_ins.sort_values('age')
df_ins.head()# index를 활용한 정렬
df_ins = df_ins.sort_index()
df_ins
1. 수치형 변수의 집계값과 히스토그램.
1.1. 수치형 변수의 집계값 계산.
df_ins['charges']df_ins['charges'].mean() #평균df_ins['charges'].sum() #합계df_ins['charges'].var(), df_ins['charges'].std() #분산, 표준편차df_ins['charges'].median() #중간값df_ins['region'].count() #관측치 수 계산하기1.2. 히스토그램 그리기
import matplotlib.pyplot as plt
import seaborn as sns아나콘다를 다운로드하였다면 matplotlib와 seaborn은 이미 다운로드 되어 있을 거다. 그래도 import는 필수..^^
df_ins['age'].plot(kind='hist')plot이라는 함수 안에 hist이라는 종류로 출력

Seaborn라이브러리로 그리는 방법입니다.
sns.histplot(data=df_ins, x='age')data=df_ins로 데이터 프레임 자체를 전달함.
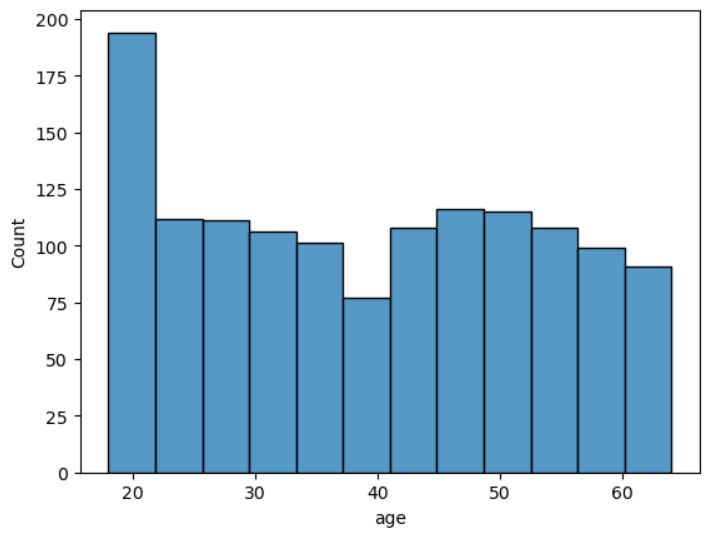
1.3. 분위수와 상자그림
최솟값(minimum, 0%), Q1(1st Quartile, 25%), 중앙값(median, 50%), Q3(3rd Quartile, 75%), 최댓값(maximum, 100%)을 사분위수(quartile)이라고 부르고, 상자그림(boxplot)으로 시각화합니다. 상자그림은 아래와 같습니다.
df_ins['charges'].quantile(0.5)df_ins['charges'].quantile([0.0, 0.25, 0.5, 0.75, 1.0])sns.boxplot(data=df_ins, y='charges')
1.4. 범주형 변수의 요약과 시각화
범주형 변수는 정해진 수준(level) 중에 하나의 값을 갖기 때문에 분석 방법이 단순하며 개수를 세면 됩니다.
- 그룹별 건수 계산과 시각화
수준별 관측치 수 계산 및 막대그래프 작성
import seaborn as sns#처음에는 df_ins를 통해서 어떠한 정보를 가져올지 탐색
df_insdf_ins['smoker'].unique() # (levels)및 개수 확인df_ins['smoker'.nunique()한 번에 코드를 다 적는 것이 아닌 하나하나 코드를 적어보며 어떠한 정보를 가져올지 선택하는 것도 좋은 방법입니다.
산점도와 상관계수의 활용
두 수치형 변수의 관계를 파악하기 위해서 산점도(scatterplot)를 그리고 상관계수(correlation coefficient)를 계산
바로 예제를 들어가 보면
import pandas as pd
import seaborn as sns
# 예제 데이터 불러오기
# 아빠키와 아들키
df_heights = pd.read_csv('./data/heights.csv')
df_heights# seaborn으로 산점도 그리기
mean_f = df_heights['father'].mean()
mean_s = df_heights['son'].mean()
print(mean_f, mean_s)
# plt.figure(figsize=(10,10))
plot_scatter = sns.scatterplot(data=df_heights, x='father', y='son', alpha=0.3)
# plot_scatter.axhline(mean_s) # 수평선 추가
# plot_scatter.axvline(mean_f) # 수직선 추가

공분산을 계산하려면,
df_heights[['father','son']].cov() #공분산
df_heights[['father','son']].corr() #상관계수이렇게 각각 공분산과 상관계수 계산 법입니다.
그룹별 집계값의 계산과 분포
- 범주형 변수를 그룹처럼 활용해서 그룹별 평균을 계산하고, 그룹별 상자그림을 그려서 그룹 간 분포를 비교
- 한 변수의 집계에서 groupby()를 추가하면 되고, 필요에 따라 agg()를 활용 가능
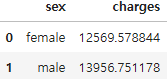
df_insdf_ins['charges'].mean() #전체 평균 계산df_ins.groupby('sex')['charges'].mean() #그룹별 평균 계산df_ins.groupby('sex', as_index=False)['charges'].mean() #그룹별 평균계산 (DataFrame 형태)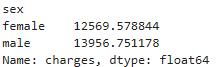
교수님께서 항상 20~30분간은 복습을 통해 다시 알려주시고 시작하십니다.
그래서 저도 그를 통해 remind 할 수 있었고, 더더욱 저의 지식이 굳혀지는 거 같네요,
나날이 늘고 있는 제 실력이지만....
집중력 흐트러지는 건 한순간이기에
다음부터는 집중력을 꽉 붙잡아 볼게요 (그렇다고 정줄 놓았다는 이야긴 아닙니당 ㅎㅎ)
