이제는 파이썬의 기초에서 벗어나 데이터 전처리 단계에 들어갔는데요, 복습 중 이었던 저에게는 그나마 편안히 열심히 들을 수 있던 수업이었어요!
pandas 라이브러리의 read_csv()등의 함수를 활용해서 데이터 불러오기 가능
아래의 데이터 파일의 경로 지정이 필요합니다
- 절대경로 : 파일의 root부터 해당 파일까지의 전체 경로를 의미한다. (단점 : 경로가 바뀌면 다시 바꿔줘야함)
- 상대경로 : 현재 파일의 위치를 기준으로 연결하려는 파일의 상대적인 경로를 적는 것을 의미합니다.
- / : root
- ./ : 현재 위치 ( 별도로 작업하지 않은 경우에는 생략 가능 )
- ../ : 상위 경로 ( 현재 폴더가 속한 폴더를 가르킴.)
%pwd를 활용하면 현재 작업하고 있는 폴더의 경로를 확인 할 수 있습니다.
시작하기 전, pandas라이브러리를 pd라고 표현해 아래와 같이 import를 통해 불러옵니다.
import pandas as pd교수님이 배포해주신 data파일 zip을 꼭 현재 실행하고 있는 ipynb 파일과 같은 폴더에 넣었습니다.
df_ins= pd.read_csv("./data/insurance.csv")
df_ins
#pandas내에 있는것을 read해서 df_ins에 저장data라는 폴더에서 insurance.csv라는 파일을 실행한다는 의미입니다.

실행해 보면 이러한 표가 나왔습니다.
여기서, 흔히 출력 할때 썼던 print를 사용 가능하지만, ui가 나오지 않기 때문에 display를 사용해서 ui도 함께 나오게 할 수 있습니다. ex) print(df_ins) → display(df_ins)
비슷하지만 series != list 입니당..
변수는 하나의 열은 변수를 의미합니다. 그래서 age라는 변수가 나오는 것입니다.
여기서 느낀점. 확통 spss랑 비슷하네?
index(rows) , columns. <-행, 열
# 타입 확인
type(df_ins)
## "DataFrame"출력 값 : pandas.core.frame.DataFrame
# 메서드의 확인(마침표 뒤에서 Tab 누르기)
type(df_ins.age)출력 값 : pandas.core.series.Series
df_ins을 마지막으로 실행 해보면,
교수님이 반복해서 하시는 말씀이 있었습니다. 내가 쓰고있는 라이브러리에서 쓰이는 메서드를 보고 싶으면 라이브러리 사이트를 이용하라고 하셨습니다.
그래서 지금 제가 활용하고 있는 pandas사이트를 들어가서 메서드를 확인하며 배워가는게 최고라고 하셨습니다.
먼저 head와 tail 메서드를 써보며 앞과 끝 몇 개의 관측치를 확인 해보겠습니다.
df_ins.head(10)
df_ins.tail(10)
다른 메서드로는 shape, index, columns, dtypes가 있습니다.
- shape : 관측치 / 변수 개수 확인
- shape[0] : 관측치의 개수만 확인
- index : 행 이름확인
- columns 변수 이름 확인
- dtypes : 변수 형식 확인
encoding = 'CP949'를 활용하여 한글 파일 읽도록 하기.
pd.read_csv('./data/고용지표_20221115084415.csv') #csv 파일의 인코딩 문제 발생#옵션 encoding = 'CP949' 추가
pd.read_csv('./data/고용지표_20221115084415.csv', encoding='CP949')# index, header 지정하여 필요없는 인덱스를 안보이도록 설정해 줍니다.
pd.read_csv('./data/고용지표_20221115084415.csv', encoding='CP949', index_col=0, header=[0,1])
이것을 응용하여 Excel파일을 불러 올 수도 있습니다.
Excel 파일은 구버전의 xls와 새로운 버전의 xlsx로 구분하며 추가 라이브러리 xlrd와 openpyxl 설치 필수 이후 pandas의 read_excel()을 사용 가능합니다.
sheet1 = pd.read_excel('./data/test.xlsx')
sheet1 #첫번째 시트 데이터 불러오기sheet2 = pd.read_excel('./data/test.xlsx', sheet_name=1, skiprows=2)
sheet2 #시트 번호 지정하고 2줄 무시하기sheet3 = pd.read_excel('./data/test.xlsx', sheet_name=2, header=None, names=['년도','건수'], na_values='-')
sheet3 #결측 저장값 지정하기
차례대로 1, 2, 3번 결과입니다.
NaN은 결측값 입니다.
하지만 DRM 보안이 적용 되어있는 Excel파일은 아래와 같이 별도의 과정을 거쳐야 합니다.
pywin32활용
import pandas as pd
import win32com.client as win32
import os
# Excel 실행
excel=win32.Dispatch('Excel.Application')
# 경로 지정 및 파일 열기
filepath = os.getcwd() +'/data/test.xlsx'
wb = excel.Workbooks.Open(filepath)
# Sheet 지정
ws = wb.Worksheets(1)
# 전체 행, 열 수 확인
nRow = ws.UsedRange.Rows.Count
nColumn = ws.UsedRange.Columns.Count
# 불러올 범위 지정
listValue = ws.Range(ws.Cells(1,1) , ws.Cells(nRow,nColumn)).Value
df_drm = pd.DataFrame(listValue[1:] , columns=listValue[0])
excel.Quit()
df_drmxlwings 라이브러리 활용
!pip install xlwings #먼저 라이브러리를 설치한 뒤 해줍시다.
import xlwings as xw
import pandas as pd
import os #라이브러리 불러오기book = xw.Book('./data/test.xlsx') #Excel 파일 열기sheet = book.sheets[0] #Sheet 선택
df_drm = sheet.used_range.options(pd.DataFrame, index = False).value
df_drm #전체 데이터 불러오기sheet = book.sheets[1]
df_drm = sheet.range("A3:C5").options(pd.DataFrame, index = False).value
df_drm #특정 부분만 불러오기xw.apps.active.quit() #종료
데이터 결합
데이터 결합으로 넘어가 봅니다.
concat()은 아래로 늘어날 때, merge()는 옆으로 늘어날 때
concat()을 활용한 동일 구조 데이터 행 결합
콜럼구조가 똑같기 때문에 이어 붙이면 됩니다.
import pandas as pd
## 출처 : 국토교통부 실거래가(http://rtdown.molit.go.kr/)
df_apt1 = pd.read_csv('./data/아파트(매매)__실거래가_20210902153616.csv', skiprows=15, encoding='CP949')
df_apt1.shapedf_apt2 = pd.read_csv('./data/아파트(매매)__실거래가_20210902153636.csv', skiprows=15, encoding='CP949')
df_apt2.shapedf_apt3 = pd.read_csv('./data/아파트(매매)__실거래가_20210902153655.csv', skiprows=15, encoding='CP949')
df_apt3.shapedf_apt = pd.concat([df_apt1, df_apt2, df_apt3], axis=0)
df_apt
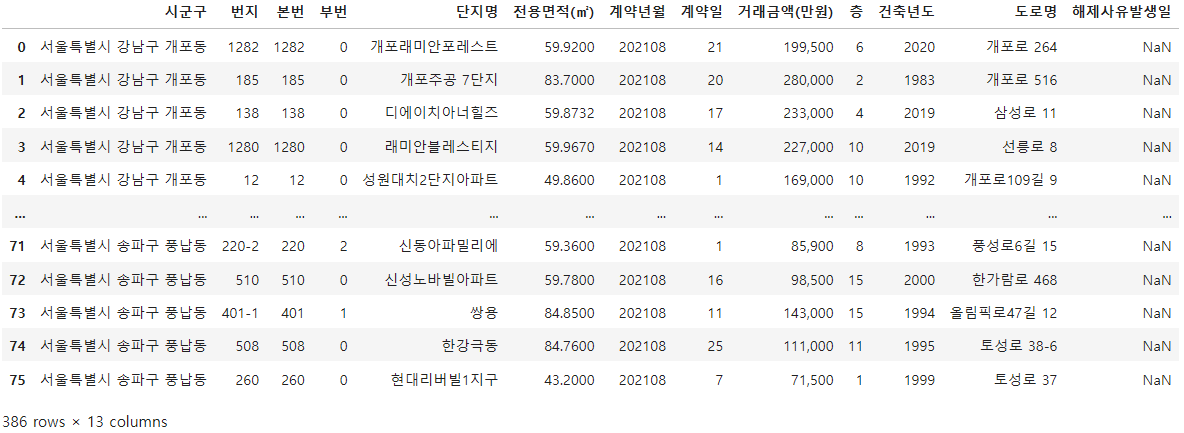
그 후, concat()을 활용해서 합쳐주고, 같은 콜롬에서 세로 방향으로 추가하는 것 이기에 축 axis = 0으로 설정해줬어요.
df_apt.indexdf_apt.loc[0] # index 0 관측치 선택
따라서 행 결합이나 정렬 이후에는 인덱스를 재지정 혹은 초기화가 필요합니다.
df_apt.reset_index()
#reset을 통한 index초기화, drop = True로 기존 인덱스를 변수로 추가할지 버릴지 선택 가능!df_apt.loc[0] #index 0 관측치 재선택
merge()를 활용한 KEY 변수 기준 결합
df_left = pd.read_csv('./data/data_left.csv')
df_right = pd.read_csv('./data/data_right.csv') #예제 데이터 불러오기df_leftdf_right
merge() : category를 기준으로 기준을 세워 양 옆을 합침
pd.merge(df_left, df_right, how='inner', on='category') # merge()를 통한 결합pd.merge(df_left, df_right, how='left', on='category') # left joinpd.merge(df_left, df_right, how='right', on='category') #right joinpd.merge(df_left, df_right, how='outer', on='category') #full outer join
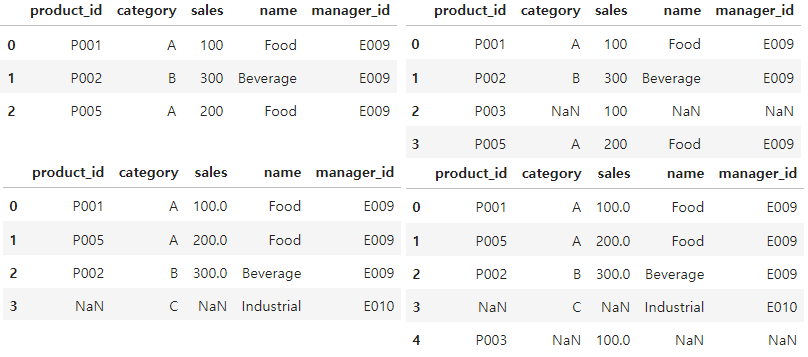
merge() 에서 how= 옵션을 활용해서 다음과 같은 같은 데이터 결합 방법을 지정.
- inner : 교집합, inner join. key 기준 일치하는 관측치만 포함
- left : left join. inner join의 결과물과 왼쪽 데이터의 짝 없는 관측치 포함
- right : right join. inner join의 결과물과 오른쪽 데이터의 짝 없는 관측치 포함
- outer : 합집합, full outer join. inner join과 양쪽 데이터의 짝이 없는 모든 관측치 포함
데이터 부분 선택
활용하는 곳 : 일반적인 비즈니스 데이터 분석에서 주제와 기간, 사이트, 제품, 공정 등 본인의 업무와 관련이 있는 일부 데이터만 선택하고 활용
import pandas as pd #예제 데이터 불러오기
df_ins = pd.read_csv('data/insurance.csv')
df_ins
1. 데이터 프레임의 변수(열) 선택 방법
- 데이터 프레임 뒤에 .을 찍고, Tab키를 눌러 메서드들과 함께 변수(열) 이름을 선택 가능
- [ ] 연산자를 활용한 변수 (열)의 선택 가능
# .을 활용한 하나의 변수(열) 선택 (공백이 포함된 변수명일 경우 사용 불가)
df_ins.age of
# 선택 문법을 통한 열 선택 (공백이 포함된 변수명일 경우에도 사용 가능)
df_ins['age of']
#데이터 프레임에서는 열의 요소들이 변수처럼 취급돼서 선택 문법인 후자의 형태 사용 추천합니다.
2. 대괄호를 활용한 데이터 부분 선택
- 데이터 프레임에 대괄호를 붙이고 :로 관측치 번호를 지정하거나 ''로 변수 이름을 넣어 데이터 부분을 선택 가능
- 변수 이름을 리스트 형식으로 묶어 넣어 여러개 변수를 한번에 선택 가능
type(df_ins['age']) # 한 변수 선택x =['age','smoker','charges']
df_ins[x] # 리스트를 활용한 복수 변수 선택df_ins[0:3] # 관측치 선택x = df_ins[['age','smoker','charges']][0:5]
x.shape[0] # 연속된 대괄호 활용가능3. loc와 iloc을 활용한 관측치 / 변수 선택
- loc은 행 이름(index)과 열 이름(column)으로 데이터에서 일부를 선택하고,
iloc은 정수(integer) 형식의 행 번호, 열 번호를 활용 - 두 방법 모두 리스트[ ]나 슬라이스:를 활용한 방법을 지원
df_ins2 = df_ins.copy()[0:10]
df_ins2 # 실습을 위해 원본 데이터를 복제(copy)하고 부분선택df_ins2['idx'] = list(range(101, 111))
df_ins2.set_index('idx', inplace=True)
df_ins2 # 실습을 위해 인덱스를 별도로 지정, inplace대신 새로 변수 가능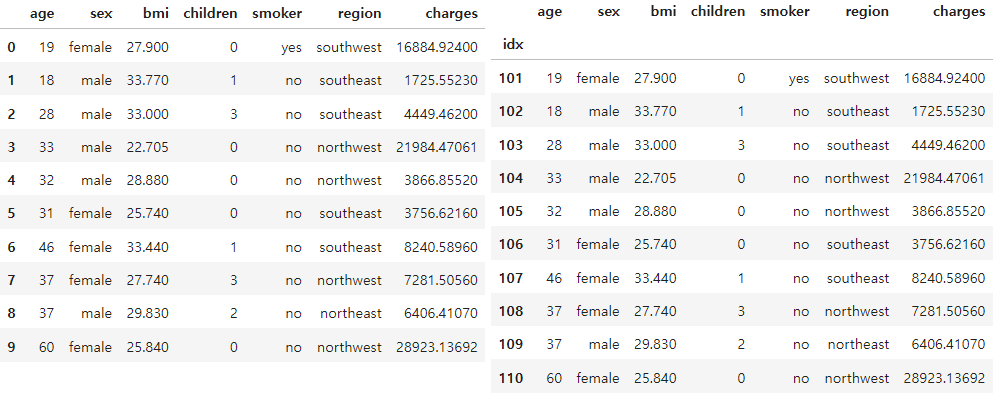
3.1. loc을 활용한 부분 선택
- loc은 실제로 눈에 보이는 index와 column을 활용
df_ins2.loc[101]df_ins2.loc[[101, 103]]df_ins2.loc[101:103]df_ins2.loc[101:103, 'smoker']df_ins2.loc[101:103, ['smoker','region']] # 변수이름 리스트 활용가능df_ins2.loc[101:103, 'smoker':'charges'] #변수이름 :를 활용 가능df_ins2.loc[:, 'smoker':'charges'] #모든 관측치를 선택할때
loc에는 위치개념이 존재하지 않아서 슬라이싱 개념이 틀림.
3.2. loc을 활용한 부분 선택
display(df_ins2)
df_ins2.iloc[0:3, [0,3,4]]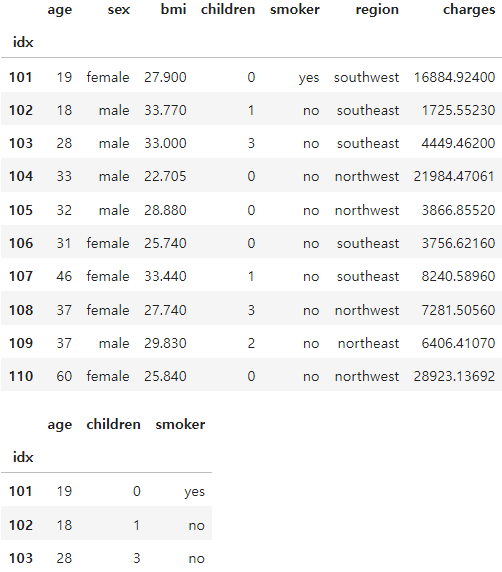
처음부터 끝까지 온전히 순공(?) 순집중하고 싶은데….
조금만이라도 놓치게 된다면 걷잡을 수 없이 나가 있는 진도여서 ….
조금 힘들었지만 오히려 더 오기가 생겨서 열심히 하고 싶어진다. 화이팅.!

'ABC 부트캠프' 카테고리의 다른 글
| [9일차] ABC 부트캠프 데이터 처리 심화_반응형 그래프 (0) | 2024.07.16 |
|---|---|
| [8일차] ABC 부트캠프 데이터 집계와 시각화(히스토그램) (2) | 2024.07.15 |
| [6일차] ABC 부트캠프 python 기초_4 (0) | 2024.07.12 |
| [5일차] ABC 부트캠프 Python 기초_3 (0) | 2024.07.11 |
| [2일차] ABC 부트캠프 seminar day! (2) | 2024.07.06 |



