40일 과정중 벌써 20일이 지났습니다..
시간이 빠른듯 천천히 흐르는데 벌써 20일밖에 안남았다는 사실에 시원 섭섭섭하네요...

import numpy as np
import matplotlib.pyplot as plt
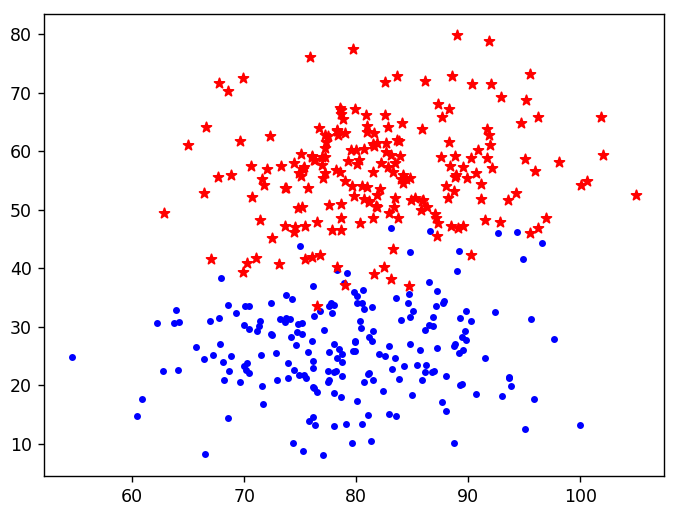
# 닥스훈트의 길이와 높이 데이터
dachshund_length = [77, 78, 88, 85, 73, 77, 73, 80] # 길이 (cm)
dachshund_height = [25, 28, 29, 30, 21, 22, 17, 35] # 높이 (cm)
# 사모이드의 길이와 높이 데이터
samoyed_length = [75, 77, 86, 86, 79, 83, 83, 88] # 길이 (cm)
samoyed_height = [56, 57, 50, 53, 60, 53, 49, 61] # 높이 (cm)
# 닥스훈트의 길이와 높이를 빨간색 점으로 시각화
plt.scatter(dachshund_length, dachshund_height, c='red', label="Dachshund")
# 사모이드의 길이와 높이를 파란색 별로 시각화
plt.scatter(samoyed_length, samoyed_height, c='blue', marker='*', label="Samoyed")
# x축 레이블 설정
plt.xlabel("Length") # 길이 레이블
# y축 레이블 설정
plt.ylabel("Height") # 높이 레이블
# 그래프 제목 설정
plt.title("DOG SIZE") # 제목
# 범례 추가 (그래프에 사용된 데이터의 설명)
plt.legend(loc="upper left") # 범례 위치 설정
plt.show() # 그래프 출력# 새로운 개의 길이와 높이 데이터
new_dog_length = [79] # 길이 (cm)
new_dog_height = [35] # 높이 (cm)
# 새로운 개의 길이와 높이를 시각화
# 'p' 마커를 사용하여 청록색으로 표시
plt.scatter(new_dog_length, new_dog_height, marker='p', c='cyan', label="New dog")
plt.xlabel("Length") # 길이 레이블
plt.ylabel("Height") # 높이 레이블
plt.title("DOG SIZE") # 제목
plt.legend(loc="upper left") # 범례 위치 설정
plt.show() # 그래프 출력# 닥스훈트의 길이와 높이를 결합하여 2차원 배열 생성
dachshund_data = np.column_stack((dachshund_length, dachshund_height))
print(dachshund_data)
print(dachshund_data.shape)
# 닥스훈트의 레이블을 생성 (모두 0으로 설정)
dachshund_label = np.array([0, 0, 0, 0, 0, 0, 0, 0]) # 닥스훈트는 0으로 레이블링
print(dachshund_label)
print(dachshund_label.shape)
# 사모이드의 길이와 높이를 결합하여 2차원 배열 생성
samoyed_data = np.column_stack((samoyed_length, samoyed_height))
print(samoyed_data)
print(samoyed_data.shape)
# 사모이드의 레이블을 생성 (모두 1로 설정)
samoyed_data_label = np.ones(len(samoyed_data)) # 사모이드는 1로 레이블링
print(samoyed_data_label)
print(samoyed_data_label.shape)
# 새로운 개의 길이와 높이를 2차원 배열로 생성
new_dog_data = np.array([[79, 35]]) # 새로운 개의 데이터
print(new_dog_data)
print(new_dog_data.shape)
# 닥스훈트와 사모이드 데이터를 결합하여 하나의 데이터셋 생성
dogs_data = np.concatenate((dachshund_data, samoyed_data), axis=0) # 행 방향으로 결합
print(dogs_data)
print(dogs_data.shape)
# 닥스훈트와 사모이드 레이블을 결합하여 하나의 레이블 배열 생성
dogs_label = np.concatenate((dachshund_label, samoyed_data_label)) # 레이블 결합
print(dogs_label)
print(dogs_label.shape)
# K-최근접 이웃 분류기 모델을 초기화
from sklearn.neighbors import KNeighborsClassifier
k = 5 # 이웃의 수
knn = KNeighborsClassifier(n_neighbors=k)
# 모델을 학습 데이터로 학습
knn.fit(dogs_data, dogs_label)
# 모델의 정확도 평가
print(knn.score(X=dogs_data, y=dogs_label))
# 학습 데이터에 대한 예측 수행
y_predicts = knn.predict(dogs_data)
print(y_predicts) # 예측 결과 출력
print(dogs_label) # 실제 레이블 출력
# 새로운 개에 대한 예측 수행
predict_new_dog = knn.predict(X=new_dog_data)
print(predict_new_dog) # 새로운 개의 예측 결과 출력
# 예측된 레이블에 따라 강아지 종류를 매핑
classes = {0:'Dachshund', 1:'Samoyed'} # 레이블과 강아지 종류 매핑
print(f"새로운 강아지는 : {classes[predict_new_dog[0]]} 라고 예측됩니다.")통계적 기반으로 데이트 증강해 보기
# 닥스훈트의 길이와 높이를 결합하여 2차원 배열 생성
dachshund_data = np.column_stack((dachshund_length, dachshund_height))
print(dachshund_data)
print(dachshund_data.shape)
# 닥스훈트의 레이블을 생성 (모두 0으로 설정)
dachshund_label = np.array([0, 0, 0, 0, 0, 0, 0, 0]) # 닥스훈트는 0으로 레이블링
print(dachshund_label)
print(dachshund_label.shape)
# 사모이드의 길이와 높이를 결합하여 2차원 배열 생성
samoyed_data = np.column_stack((samoyed_length, samoyed_height))
print(samoyed_data)
print(samoyed_data.shape)
# 사모이드의 레이블을 생성 (모두 1로 설정)
samoyed_data_label = np.ones(len(samoyed_data)) # 사모이드는 1로 레이블링
print(samoyed_data_label)
print(samoyed_data_label.shape)
# 새로운 개의 길이와 높이를 2차원 배열로 생성
new_dog_data = np.array([[79, 35]]) # 새로운 개의 데이터
print(new_dog_data)
print(new_dog_data.shape)
# 닥스훈트와 사모이드 데이터를 결합하여 하나의 데이터셋 생성
dogs_data = np.concatenate((dachshund_data, samoyed_data), axis=0) # 행 방향으로 결합
print(dogs_data)
print(dogs_data.shape)
# 닥스훈트와 사모이드 레이블을 결합하여 하나의 레이블 배열 생성
dogs_label = np.concatenate((dachshund_label, samoyed_data_label)) # 레이블 결합
print(dogs_label)
print(dogs_label.shape)
# K-최근접 이웃 분류기 모델을 초기화
from sklearn.neighbors import KNeighborsClassifier
k = 5 # 이웃의 수
knn = KNeighborsClassifier(n_neighbors=k)
# 모델을 학습 데이터로 학습
knn.fit(dogs_data, dogs_label)
# 모델의 정확도 평가
print(knn.score(X=dogs_data, y=dogs_label)) # 모델의 정확도 출력
# 학습 데이터에 대한 예측 수행
y_predicts = knn.predict(dogs_data)
print(y_predicts)
print(dogs_label)
# 새로운 개에 대한 예측 수행
predict_new_dog = knn.predict(X=new_dog_data)
print(predict_new_dog)
# 예측된 레이블에 따라 강아지 종류를 매핑
classes = {0:'Dachshund', 1:'Samoyed'} # 레이블과 강아지 종류 매핑
print(f"새로운 강아지는 : {classes[predict_new_dog[0]]} 라고 예측됩니다.")
필기체


from sklearn import datasets, metrics
# 손글씨 숫자 데이터셋을 로드
digits = datasets.load_digits()
print(digits)
# 두 번째 숫자의 데이터 형태 출력
print(digits.data[1].shape)
import matplotlib.pyplot as plt
# 두 번째 숫자의 이미지를 회색조로 시각화
plt.imshow(digits.images[1], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()import numpy as np
from sklearn.model_selection import train_test_split
# 데이터를 훈련 세트와 테스트 세트로 분할 (70% 훈련, 30% 테스트)
(X_train, X_test, y_train, y_test) = train_test_split(np.array(digits.data),
digits.target, test_size=0.3,
random_state=42)
k = 5 # K-최근접 이웃에서 사용할 이웃의 수 설정
from sklearn.neighbors import KNeighborsClassifier
# KNN 분류기 초기화
knn = KNeighborsClassifier(k)
# 훈련 데이터를 사용하여 모델 학습
knn.fit(X_train, y_train)
print(knn.score(X_train, y_train))
# 테스트 세트에 대한 예측 수행
y_predictions = knn.predict(X_test)
print(y_predictions)
print(y_test)
print(metrics.accuracy_score(y_test, y_predictions))
# 첫 번째 테스트 이미지 시각화
plt.imshow(X_test[0].reshape(8, 8), cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
# 첫 번째 테스트 이미지에 대한 예측 수행
y_predict = knn.predict(X_test[0].reshape(1, -1))
print(y_predict)
print(y_test[0])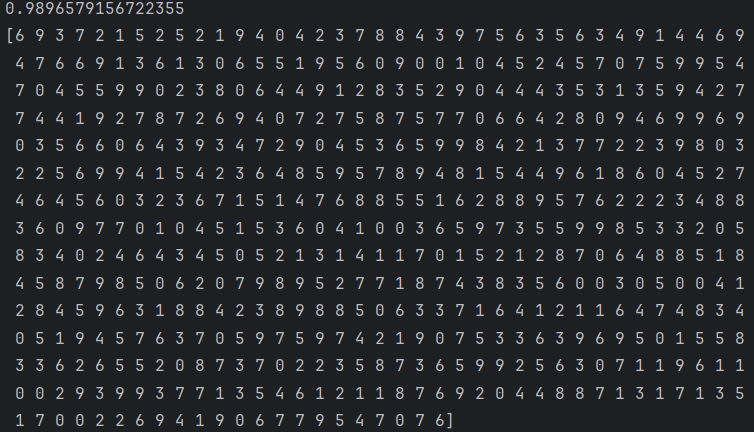

선형회귀 실습

# 입력 데이터와 목표 변수 정의
X = [[174],
[152],
[138],
[128],
[186]]
y = [71, 55, 46, 38, 88]
print(X)
print(y)
import numpy as np
# 리스트를 NumPy 배열로 변환
X = np.array(X)
y = np.array(y)
from sklearn.linear_model import LinearRegression
# 선형 회귀 모델 초기화
lr = LinearRegression()
# 모델 학습 (X를 독립 변수, y를 종속 변수로 사용)
lr.fit(X=X, y=y)
# 학습 데이터에 대한 결정 계수 (R^2 값) 출력
print(lr.score(X=X, y=y))
# 새로운 데이터에 대한 예측 수행
y_predict = lr.predict(np.array([[178]]))
print(y_predict)
from matplotlib import pyplot as plt
# 기존 데이터에 대한 예측값 계산
y_predicts = lr.predict(X)
# 예측값을 파란색 별표로, 실제 데이터를 빨간색 원으로 시각화
plt.scatter(X, y_predicts, color='blue', marker="*")
plt.scatter(X, y, color='red', marker='o')
plt.show()
암담하군요.. 이제는 라임에듀를 병행하며 복습을 해야할 거 같아요.. 인공지능 머시러닝 너무 어려워요..
그래도 극복해내며 열심히 해보도록 하겠습니다!

'ABC 부트캠프' 카테고리의 다른 글
| [22일차] ABC 부트캠프 인공지능_4 (0) | 2024.08.03 |
|---|---|
| [21일차] ABC 부트캠프_ESG데이 (0) | 2024.08.02 |
| [19일차] ABC 부트캠프 인공지능_2 (0) | 2024.07.31 |
| [18일차] ABC 부트캠프 인공지능_1 (0) | 2024.07.31 |
| [17일차] ABC 부트캠프_건양대학교 메디컬 캠퍼스 견학 (0) | 2024.07.28 |



